이전에 쓴글
교보문고 Python 으로 베스트셀러 정보 가져오기 (스크레이핑)
교보문고 베스트셀러 페이지에서 Python 으로 랭킹정보를 가져오는 간단한 스크레이핑에 대해 설명하겠습니다. 먼저 교보문고의 베스트셀러 정보 제공 페이지의 URL 은 http://www.kyobobook.co.kr/bestSell
vuxy.tistory.com
에서 문제점이라면 문제점이 하나 있습니다.
한번 가져올때 데이터가 20개씩뿐이라는거죠.
디폴트로 화면상에 20개씩 뿌려주고 있고 ,
다음페이지로 이동할때도 링크에 마우스를 얹어보니 javascript 로 데이터를 주고 받는 듯하니
어떤 파라미터들을 넘기고 있는지 html 소스를 확인해봐야할듯합니다.
베스트셀러 페이지인
http://www.kyobobook.co.kr/bestSellerNew/bestseller.laf?orderClick=d79 에 접속을 해서 확인을 해보면
아래 이미지처럼 20개씩보기 , 50개씩보기 버튼이 있습니다.
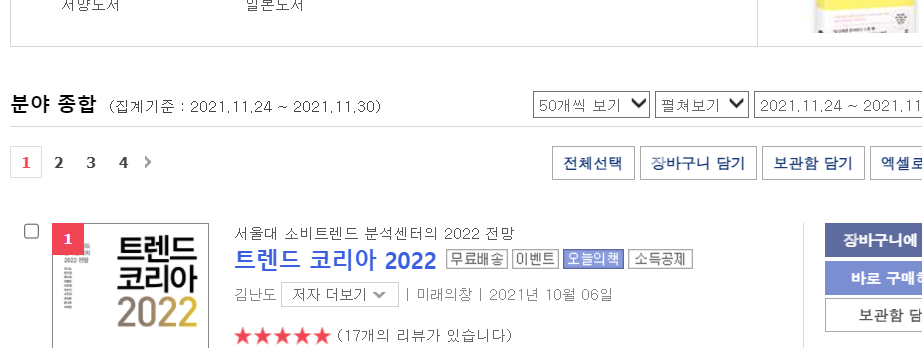
여기에 마우스를 가져가보니 자바스크립트의 setPerPage() 를 사용하네요.
소스보기로 함 찾아보겠습니다.
//Set PerPage (20, 50)
function setPerpage(perpage){
document.frmList.perPage.value=perpage;
getBestseller();
}perPage 라는 변수에 값을 넣고 있네요. 일단 체크.
다시 소스로 돌아가서... 보니
<!-- 최 상위 영역 -->
<form name="frmList" id="frmList" method="post" action="/bestSellerNew/bestseller.laf">
<input type="hidden" name="targetPage" value='' />
<input type="hidden" name="mallGb" value='KOR' />
<input type="hidden" name="range" value='1' />
<input type="hidden" name="kind" value='0' />
<input type="hidden" name="kyoboTotalYn" value='N' />
<input type="hidden" name="selBestYmw" value='2021114' />
<input type="hidden" name="linkClass" value='A' />
<input type="hidden" name="cateDivYn" value='' />
<input type="hidden" name="pageNumber" value='1' />
<input type="hidden" name="perPage" value='20' />
<input type="hidden" name="excelYn" value='N' />
<input type="hidden" name="seeOverYn" value='Y' />
<input type="hidden" name="loginYN" value="N"/>이렇게 파라미터 설정 부분이 있네요.
POST 로 각각의 값들을 넘기고 있습니다.
그리고 디폴트로 perPage 에 20 이 값이 들어가고 있습니다.
그럼 URL 로 html 파싱하기 위한 방법을 좀 바꿔보겠습니다.
이전 GET 으로 단순하게 가져올때는
from urllib.request import urlopen
from bs4 import BeautifulSoup as bs
# 교보문고 베스트셀러 URL
url = "https://www.kyobobook.co.kr/bestSellerNew/bestseller.laf?orderClick=d79"
html = urlopen(url)
soap = bs(html, "html.parser")으로 했습니다만
POST 를 필요한값들을 넘겨야 하기에
from bs4 import BeautifulSoup as bs
from urllib import request, parse
data = parse.urlencode({'perPage': '500'}).encode()
req = request.Request("http://www.kyobobook.co.kr/bestSellerNew/bestseller.laf", data=data)
html = request.urlopen(req)
soap = bs(html, "html.parser")로 perPage 에 500 값을 넣어서 불러서 값을 출력해보면
196: 주린이가 가장 알고 싶은 최다질문 TOP 77(교보 단독 리커버)
197: 그러라 그래(양장본 HardCover)
198: 부의 시나리오(교보 단독 20만 부 기념 리커버 에디션)
199: 지옥. 1
200: 죽이고 싶은 아이(우리학교 소설 읽는 시간)200 개 까지의 랭킹이 출력됩니다.오~~ 지옥 랭킹에 올라있네요.
아하~~ 최대 200개까지로 정해져있구나를 알 수 있습니다.
코드를 정리하면
from bs4 import BeautifulSoup as bs
from urllib import request, parse
data = parse.urlencode({'perPage': '500'}).encode()
req = request.Request("http://www.kyobobook.co.kr/bestSellerNew/bestseller.laf", data=data)
html = request.urlopen(req)
soap = bs(html, "html.parser")
# 집계기준 날짜
statistics_date = soap.find('h4', {'class': 'title_best_basic'}).find('small').text
bestseller_contents = soap.find('ul', {'class': 'list_type01'})
bestseller_list = bestseller_contents.findAll('div', {'class': 'detail'})
# 제목
title_list = [b_detail.find('div', {'class': 'title'}).find('strong').text for b_detail in bestseller_list]
cover_list = bestseller_contents.findAll('div', {'class': 'cover'})
rank_list = [cover.find('strong', {'class': 'rank'}).text for cover in cover_list]
for i in range(len(title_list)):
print(rank_list[i]+": "+title_list[i])
print("-------------------------")
print(statistics_date)이렇게 해서 교보문고 주간 랭킹 정보 가져올때 20개보다 많이 가져오려면 어떻게 하는지 알아 봤습니다.
다음에는 다른 파라미터들은 어떤 값들을 가지고 있는지 알아보겠습니다.
참고
교보문고 Python 으로 베스트셀러 정보 가져오기 (스크레이핑)
교보문고 베스트셀러 페이지에서 Python 으로 랭킹정보를 가져오는 간단한 스크레이핑에 대해 설명하겠습니다. 먼저 교보문고의 베스트셀러 정보 제공 페이지의 URL 은 http://www.kyobobook.co.kr/bestSell
vuxy.tistory.com
'iaa.dev > Python' 카테고리의 다른 글
| 교보문고의 연간 베스트셀러 가져오기- 3 (0) | 2021.12.03 |
|---|---|
| 교보문고 Python 으로 베스트셀러 정보 가져오기 (스크레이핑) (0) | 2021.12.02 |


댓글